It will be shown that access control lists are a degenerate case of the generic packet classification problem, but that different domains have different classification needs, and a single packet classification is often not possible or perhaps even desirable. Also, it will be shown that classification in these different domains often are best served by quite different algorithms or hardware assisted lookups.
Table of Contents
- Introduction
- Classification Requirements
- Classification Infrastructure
- Deterministic Classification
- Intrusion Detection and Classification
- Conclusion
Introduction
Packet classification has been growing in importance within the Internet as the requirements expand to selectively recognize and process packets differently, as a result of security concerns [1, 2], policy control, differentiated services [3], intrusion detection [4], or other needs. The requirements for packet classification has been increasing in two directions:- Traditionally, packet classification has occurred on the edge of networks, especially in the security or access control domain. With the growing need for end-to-end differentiated services network, packet classification is now being performed throughout the network on a hop-by-hop basis. This is placing much greater demands on the performance of packet classification within network devices which traditionally have not been required to classify packets.
- The number of applications that require packet classification is growing rapidly. Within a single network device, a single packet traversing through the device may need to be matched against one or more security access lists, quality of service queueing selection, intrusion detection monitoring and signature matching, network address translation etc.
The essential nature of the problem is seen to be a packet classification issue, but with the different domains of security and QoS, the rules that are used for the classification are very different. It is argued that a single level of packet classification cannot meet all the needs of the different classification clients, excepting established flow semantics (where the classification will have to be made at flow establishment). Different clients require different classification rules.
Furthermore, the different domains that the classification operates in often have attributes that restrict or govern the appropriateness of the classification algorithms; for example, access lists normally have sequential ordering semantics, where the first matching access control element is the rule to be used, and any algorithm or hardware assist must preserve this semantic. In full-flow matching, used in dynamic firewall security lists, the ordering semantics are not valid, since only one flow can match - the classification algorithm can take advantage of this, and avoid the ordering limitations. In static access control lists, the mean time between changes can be very long, since they are normally user-configured, whereas with flow-related firewall entries, these are highly dynamic, maybe undergoing hundreds of changes per second.
Therefore, we can see that classification algorithms vary according to the domain the algorithm operates in. It is very unlikely that a single algorithm can successfully work in all domains.
The solution is to allow multiple algorithms to operate, according to
the requirements of the domain. To do this, an infrastructure must exist
whereby new algorithms can be incorporated easily, such as algorithms designed
for intrusion detection, or dynamic class-of-service classifiers etc. It
will be shown how these algorithms can take advantage of hardware assist.
Classification Requirements
There are many applications within networks that require some form of packet classification; at its most base level, classification can be seen as a simple de-encapsulating or demultiplexing of incoming packets. Routing of network packets can be viewed as a case of matching a packet field (the destination address) to a particular rule (a routing table). Other applications such as security access lists or transport layer port number matching for quality of service are generally considered to be the main clients of packet classification, because they classify packets using more than just destination network addresses, or they understand or remember some state using the packet. At the most basic level, packet classification can be considered as:Match a packet against a set of rules, and perform an action associated with the matching rule(s).The problem is, however, that different applications can have widely varying attributes that predetermine certain characteristics of the rules or actions. This greatly affects the ability to implement packet classification within the contraints of typical networking hardware. To compound the problem, the different application attributes are often at cross-purposes, or are sometimes mutually exclusive. To illustrate this, it is instructive to examine the attributes of some of the classification applications:
Static Access Control Lists
Access control lists have been used in the Internet for many years to provide packet filtering, security control etc. A typical access control list appears thus:Firewall/reflexive flow matchingaccess-list 104 permit igrp 0.0.0.0 255.255.255.255 0.0.0.0 255.255.255.255
access-list 104 permit icmp 0.0.0.0 255.255.255.255 0.0.0.0 255.255.255.255
access-list 104 permit tcp 0.0.0.0 255.255.255.255 172.23.100.0 0.0.0.255 eq 23
access-list 104 permit tcp 0.0.0.0 255.255.255.255 172.23.100.0 0.0.0.255 eq 20
access-list 104 permit tcp 0.0.0.0 255.255.255.255 172.23.100.0 0.0.0.255 eq 21
access-list 104 permit tcp 0.0.0.0 255.255.255.255 172.23.100.0 0.0.0.255 gt 987
access-list 104 deny tcp 0.0.0.0 255.255.255.255 0.0.0.0 255.255.255.255 gt 5000
access-list 104 permit tcp 0.0.0.0 255.255.255.255 0.0.0.0 255.255.255.255 gt 987
access-list 104 deny udp 0.0.0.0 255.255.255.255 0.0.0.0 255.255.255.255 gt 1660
access-list 104 permit udp 0.0.0.0 255.255.255.255 0.0.0.0 255.255.255.255 gt 1599The processing of the access list is simple. The packet is matched against each rule in turn until a matching rule is discovered. The packet is then permitted or denied according to the keyword. Access list entries may have wildcards or address masking, which allows selected fields to be ignored. Transport layer port numbers can be set up as ranges etc. The sequential nature of the matching semantics is important, as access control lists are designed to be scanned in the order they have been written, so that a more generic matching rule with a different action can occur after more specific rules, allowing fine control over the packet matching.
Access lists are typically configured by a user, and installed every time there is a change to the configuration. Generally, changes are not frequent (not within the timeframe of typical packet flows, more like in the scale of hours or days rather than seconds or minutes).
Because of the nature of access lists, having to explicitly define addresses, port numbers etc, it is often the case that the access list can grow to an unmanageable size, sometimes having hundreds or thousands of entries. This can also have a detrimental effect on performance if the access list is processed by a sequential check of the rules.
Given the requirement for sequential checking, it is difficult to use hashing or other techniques to speed the search.
Often, IP firewalls operate by monitoring transport level flows, and allowing flows to traverse the firewall for the life of the flow. If a transport level packet is received that does not match any of the active flows, it may be discarded or flagged etc. Typically, the firewall is configured with a set of rules indicating the flows that are allowed e.g protocol types, source or destination hosts or networks etc. Sometimes, user level verification or authorisation is included.Congestion ControlWithin a router being used as a firewall in this manner, once the flow is established, packets are matched against the established flows to check whether the packet is permitted through the router. Sometimes static access lists are used to configure the rules for the establishment of the flow, and then a dynamic internal list is maintained for each of the flows.
This flow table is different from static access lists in that no wildcard matching is required, as the flow entry contains a complete record of the source and destination addresses, transport level port numbers etc. The full packet header must be used to compare the flow; this lends itself well to using hashing techniques on the entire header to quickly lookup the flow.
Furthermore, the flow table is highly dynamic, with flows being added and removed constantly, sometimes on the order of hundreds or thousands a second. The flow table is usually populated internally as flows are detected as being established.
Packet classification for congestion control is usually configured as a set of rules defining queue priorities for selected protocols [ 5 ] to allow management of the packet queues internal to a network device. Typically, a queueing algorithm will classify the packet, maybe with user configured parameters, and ensure higher priority packets are not dropped or delayed. When configuring such parameters, access lists are often used to provide the rules - rather than first match, a more appropriate matching criterion may be best match. The parameters used to adjust the queueing algorithms may be user settable, or may be dynamic depending on network load or congestion.Security/policyMost classification used for congestion control is based on transport layer parameters (protocol, port number, connection state) rather than network addresses (though the IP precedence bits are starting to be listened to as well, finally).
A growing trend that is appearing is the use of external policy managers, where separate management stations are configured to disseminate sophisticated policy control to individual network devices. Often these are linked to security authorisation and authentication systems. This allows a much higher level of control of the network, providing more reliable overall quality of service according to the policies desired.Intrusion DetectionThe network device's roles in this scenario are often limited to forwarding packets of interest to the policy manager, and responding to specific requests from the policy manager to install new classification rules and actions so that packets can be dealt with accordingly. The rules and classification tables may be quite dynamic, with many changes taking place over a short period of time. The matching of rules is again likely to be best match, as opposed to first match. There may be times when a set of rules that define packets of interest is installed - in this instance, perhaps the set of rules that match is required.
The use of intrusion detection as a security measure is starting to become widespread. Specialised intrusion detection systems are installed that promiscuously listen on networks, tracking network connections, matching known intrusion patterns (signatures), and signalling events. With higher speed connections, however, there is a performance and scaling issue - one approach to solving this is to integrate a packet tap within the network device that can recognise packets of interest, and forward these to the specialised intrusion detection device for more intensive examination. It is possible that some feedback to the network device may then enable new sets of rules to catch later packets.There are other applications that certainly require packet classification, but the applications listed suffice to cover a spectrum of the possible applications.For a network device to act as a useful filter in this way, it is likely that a large number of signature rules must be used to classify the packet. A desirable result from the classification would be all the matching signatures, not just the first or best match.
Table 1 summarises the characteristics of these applications in terms
of classification attributes.
| Type | Field Matching | Ordering | Configuration | Volatility |
| Static ACL | Partial, wildcard | First match | User configured | Low |
| Firewall/flow | Full packet | Exact match | Internal dynamic | High |
| Security/Policy | Variable | Best match | External dynamic | High |
| Congestion control | Partial | First or best match | User configured | Low |
| Intrusion Detection | Partial | All matching | External Dynamic | Medium |
Classification Infrastructure
The goals of a classification infrastructure are to provide a framework for applications that have packet classification requirements to integrate cleanly with classification algorithms. A key feature of this infrastructure is the ability to link multiple packet matching modules together so that different algorithms can be incorporated as part of a single packet classification operation. This design pattern is known as a Chain of Responsibility, where separate modules may have different internal algorithms or details, but each module presents a common interface to the calling software. Each module is invoked in turn, until one module indicates that a successful match has occurred (Figure 1).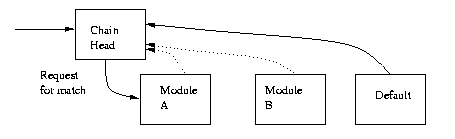
For example, for a typical router's access control lists, the following chain would be possible (figure 2):Figure 1: Chain of Matching
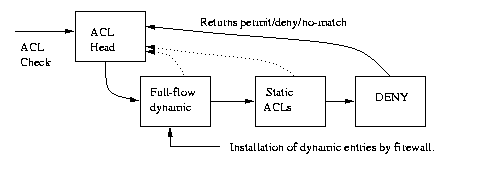
The advantage of using a separate module for each access list type is that a different classification algorithm can be used to find a rule match for each module. The full-flow entries can use a hash or hardware assist lookup, since an exact match is required. With the wildcarded static ACLs, the first match must be found, either via a sequential search or by using a more sophisticated lookup algorithm,Figure 2: Access List..
One observation to be made is that access lists are really a specialised packet classification operation, where the single result is either a permit or deny. If the permit/deny result is considered a degenerate action from a rule lookup, then access lists can be incorporated into a more generic packet classification model, allowing the same classification algorithms to be employed for all classification applications. More importantly, as new applications develop new requirements, new algorithms can be developed to optimally cater for these requirements.
An infrastructure for packet classification is shown in figure 3:
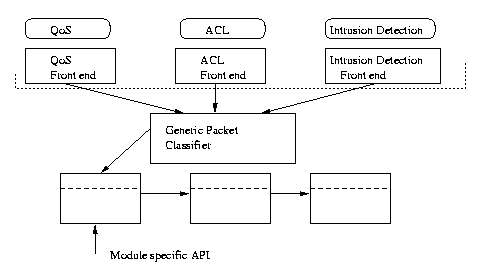
The infrastructure is designed to allow specialised hardware assist to be used in any of the classification modules, or for different modules to have tailored algorithms befitting the particular lookup characteristics of the rules.Figure 3: Generic packet classifier infrastructure.
Deterministic Classification
The theoretical nature of packet classification is well understood [ 7 ], though the main challenge is implementing a solution that is scalable, inexpensive and flexible. As described previously, essentially packet classification is the matching of a packet against a set of rules, with actions or parameters attached to the rules. The key area of interest is the mechanisms used to express the rules and match the packet. To summarise, each rule contains packet header specifications typically including the following header fields:| Header Field | Size | Attrributes |
| IP Source Address | 32 bits | IP Dotted address, 32 bit mask (sometimes non-contiguous) |
| IP Destination Address | 32 bits | Same as IP source address |
| Protocol | 8 bits | Numeric value 0-255 defining transport layer protocol |
| Precedence/TOS | 8 bits | 3 bit precedence value and 5 bits of type of service flags |
| Header field | Size | Attributes |
| TCP/UDP Source port number | 16 bits | Numeric range value e.g 512-1000 |
| TCP/UDP Destination port number | 16 bits | Same as source port number |
| TCP control bits | 5 bits | Defines stream state (Established etc.) |
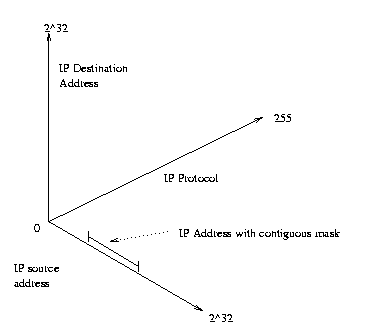
Given the linear ranges of the fields, values and ranges belonging to these fields can be expressed as points and lines respectively on the axis of the field. A rule that specifies a source and destination address and mask along with a particular IP protocol (e.g TCP) can be used to map out a region in this space:
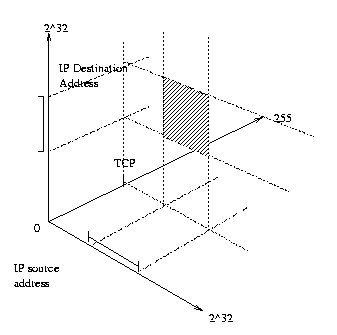
A packet to be classified that contains an IP source and destination address and protocol number appears in this graph as a point. The matching operation is essentially determining if the point lies within the region specified by the rule. Multiple rules specify multiple (possibly overlapping) regions or points in the graph, so that a single packet may fall within multiple regions, representing different rules - this means that multiple rules may match a single packet.
Incorporating other packet fields in the rule matching simply increases the number of dimensions in the graph. Mathematically, thus, packet classification is a point location problem in N-dimensional space [ 7 ], and can be treated as such. The main difficulty lies in two areas:
- The number of rules involved can be large, in the order of hundreds or thousands.
- The number of dimensions is typically large, with up to 7 or 8 different fields being involved in the matching process.
- Language based rule descriptions [ 8 , 9 ], that use a descriptive language to define the rules, which are then compiled and optimised for run-time processing. For performance, often a dedicated hardware engine is designed to operate the run-time form of the rules.
- Table or lookup based [ 7 , 10 ], where memory lookups are done using tries etc.
- Memory usage. A trivial treatment shows that fields can be concatenated and used as a single memory lookup, but the number of bits rapidly grows to an unmanageable size (just a single IP address requires 32 bits of memory address range). A common approach is to use tries to reduce the memory usage.
- Lookup time. In the same way that multiple fields can be concatenated together for a single lookup, a field can sometimes be split to add a new dimension to the graph - this is applicable to larger fields such as IP addresses, which are often split for trie lookups. This can increase the number of lookups and memory references required.
- Number of rules. As the number of rules increase, the complexity of the classification tables can rapidly increase. With language based classification, this can lead to non-determinism and worst-case performance if the packets being matched do not conform to the optimisation expectations of the language.
- Often, hashing is used to lookup rules. Hashing works well when the rules do not contain wildcards, but otherwise the generation of the hash tables can be problematic.
- Hardware acceleration of classification is necessary with high speed network devices. Similar to the designs in LAN switches, CAMs are often used as the hardware acceleration devices. Similar to hashing, this works well for matching specific items, but doesn't handle wildcarded items well.
- Parallel lookups. A common approach to accelerating classification is to use concurrent lookups. This can decrease dramatically the run-time delays, but the cost of providing a large number of memory paths is often high.
- Matching semantics. Access lists are an example of classification rules where the matching semantics dictate that the first matching rule should be used. Other applications may require that the best matching rule (e.g IP address lookup) is used, or even that a list of matching rules is provided. Some classification algorithms do not easily provide a first match (e.g. trie lookup), and so must be post-processed to obtain this.
- Volatility of entries. Adding and removing rules can cause considerable churn in classification tables, often causing recompilation of tables or re-optimisation of rules. If the classification application needs to deal with entries that are dynamic in nature, such as firewall flows, this may limit the applicability of certain algorithms that are high in CPU cost (but have desirable run-time qualities).
- One approach to limiting memory usage has been to build classification tables dynamically i.e as packets are processed or streams appear for the first time, the packet is classified according to the rule set, and a cache entry is built. This reduces the CPU requirements for pre-generating large amounts of data, but adds overhead to packet processing.
The goal of packet classification is to provide a deterministic rule matching of a packet in minimum time, with minimum cost. There are many factors involved, and it is unlikely that a single algorithm or classification scheme can suit every application or situation. Rather than attempt to provide a 90% solution, one approach is to allow multiple classification algorithms to operate in an infrastructure described earlier, so that different applications can select the appropriate algorithm.
Cisco is using, enhancing and developing several such algorithms, with very promising results. [Some final later results will be included here].
Intrusion Detection and Classification
Normally, packet classification results in a single action associated with a rule (e.g permit or deny with access lists). Classification algorithms often rely on this, so that the lookup will retrieve this particular value. This is generally adequate for most classification needs, but newer applications are emerging that would benefit from a more flexible classification scheme. Two schemes are examined whereby a single lookup can provide more information to the application.With intrusion detection, a common approach is to have a packet tap within a network device that recognises packets of interest, and forwards them to a specialised IDS (Intrusion Detection System) for further processing. The packet tap itself should be low overhead, but should be discriminating enough so that only interesting packets are captured. One problem is that the number of `interesting packets' can be quite high, so instead of forwarding all to the IDS, the network device should compare the packet to a set of signatures to determine if the packet matches a known intrusion attempt. A further problem is that the list of signatures can be extensive, so a scaling and performance bottleneck can be hit if a large number of packets are attempted to be matched against all signatures.
A classification algorithm that Cisco is using and developing employs
bitmaps to represent rules. After a packet is classified, instead of a
single action or first or best matched rule, a bitmap of the matching rules
is obtained. This can then be used to determine the first matching rule,
or used to indicate if a packet should be forwarded onto the IDS:
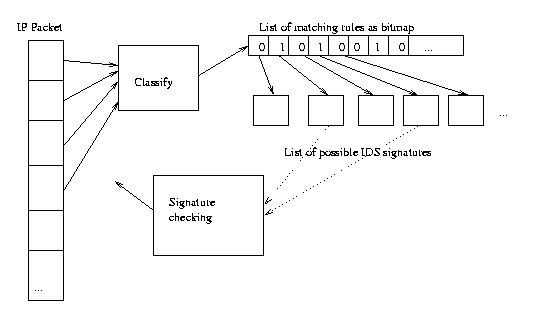
The main advantage of this approach is that the IDS signature matching
can be incorporated into the normal classification of the packet, reducing
considerably the overhead of forwarding packets to a specialised IDS.
Conclusion
An infrastructure for packet classification was presented, based on providing a generic packet classification chain of responsibility suitable for processing packets for access list requirements (which is a degenerate case of classification). The infrastructure allows different classification algorithms to be used for different rule sets. The use of separate algorithms opens the way for efficient, deterministic packet classification.Finally, it was shown how packet classification could be incorporated as part of an Intrusion Detection System packet tap by providing a list of IDS signatures to check on matching interesting packets.
References
[1] B. Fraser. Site Security Handbook RFC 2196[2] E. Guttman, L. Leong, G. Malkin. Users' Security Handbook RFC 2504
[3] S. Blake, D. Black, M. Carlson, E. Davies, Z. Wang, W. Weiss. An Architecture for Differentiated Services RFC 2475.
[4] T. H. Ptacek, T. N. Newsham. Insertion, Evasion and Denial of Service: Eluding Network Intrusion Detection.
[5] B. Braden et. al. Recommendations on Queue Management and Congestion Avoidance in the Internet RFC 2309
[6] E. Gamma, R. Helm, R. Johnson, J. Vlissades. Design Patterns: Elements of Reusable Object-Orientated Software. Addison-Wesley 1995.
[7] T.V. Lakshman, D. Stiliadis. High-Speed Policy-Based Packet Forwarding Using Efficient Multi-dimensional Range Matching. In Proceedings of ACM SIGCOMM'98, pages 203-214.
[8] M.L. Bailey, B. Gopal, M. Pagels, L.L. Peterson, P. Sarkar. PATHFINDER: A Pattern Based Packet Classifier. In Proceedings of the First Symposium on Operating Systems Design and Implementation, November 1994.
[9] D.R.Engler, M.F.Kaashoek. DPF: Fast, Flexible Message Demultiplexing Using Dynamic Code Generation.
[10] V. Srinivasan, G. Varghese, S.Suri, M. Waldvogel. Fast and Scalable Layer Four Switching.
[11] Y. Rehkter, B. Davie, D.Katz, E. Rosen, G.Swallow. Cisco Systems' Tag Switching Architecture Overview