Toaster: A High Speed Packet Processing Engine

Andrew McRae
Distinguished Engineer
Cisco Systems Australia
Email: amcrae@cisco.com
Abstract
The Internet explosion has become a reality, where the number of users
and the amount of data traversing the Net has doubled several times in
the last few years. Whilst this has changed the way we work, live
and play, the plumbers responsible for keeping the bits flowing have sometimes
had a hard time keeping up with the dramatic growth in demand for services
and bandwidth.
In the last 5 years the equipment used to run the Internet has morphed
from simple routers to optical switches. In conjunction with this,
the advent of the so-called New World of telecommunications (where traditional
connection driven modes of voice and service delivery is being supplanted
by integrated Internet Protocol services) has demanded new levels of intelligent
classification and control.
One effect of this demand is the development and introduction of specialised
processing engines dedicated to networking, generally termed Communication
Processors. Some of these range from simple microcoded engines to
full blown dedicated CPUs.
This presentation examines the evolution of this class of processors,
and discusses the underlying motivations and requirements.
Introduction
With the rapid deployment of integrated digital networks, there is a vast
demand for higher speed and more sophisiticated devices to run these networks.
This paper examines one aspect of the developments required to meet this
demand, that of the design and implementation of a new specifialised communications
processor.
Cisco has traditionally been a user of off-the-shelf processors (including
Communication Processors), but it has been clear with the growing demand
for faster and more powerful switches that developing Cisco's own Communication
Processor would be the only way of delivering products that met the challenge.
This presentation describes the result of this effort from a technical
viewpoint, officially known as PXF (Parallel eXpress Forwarder), but nicknamed
Toaster (which is a lot easier to say).
The architecture of the processor is described, highlighting areas where
the processor was specifically tailored for processing packets, and showing
how such a processor differs significantly from typical CPUs. The
challenges of building such a processor are described, and some results
presented indicating how processing compares to more traditional packet
forwarding methods.
New Technologies and Features
There are two basic pressures that exist in the development of new Internet
devices; bandwidth and features.
The bandwidth pressure stems from the large scale deployment of Internet
related communications using new (xDSL) and existing technologies (ISDN),
and from the deployment of newer technologies such as:
-
Gigabit Ethernet. Newer laser and fibre optic technology now allows Gigabit
Ethernet to operate at distances upwards of 70 or 80 Kms. Gigabit ethernet
is now being used as high speed uplinks for service providers and enterprise
organisations, as well as high speed trunks within a building. The ubiquitous
nature of ethernet and the ease of interconnection has created an infrastructure
that will seamlessly operate across 3 orders of bandwidth magnitude (from
10MBit/s up to 10GBi/ts).
-
Fibre optic. The reselling and availability of so-called `dark' fibre (i.e
fibre optic connections where the customer provides the equipment at each
end without an intervening provider dictating the connection protocol)
has allowed the deployment of POS (Packet Over Sonet) interconnects at
speeds ranging from OC-3 up to OC-192.
-
Wireless Technology. Higher and higher speeds are now available for wireless
operation, and rapid development of new protocols for metropolitan area
wireless networking and the emergence of devices that incorporate wireless
technology will accelerate this market.
In Australia, we are somewhat sheltered from the harsh and unforgiving
world of high bandwidth availability to the average user, presumably because
if we had high bandwidth, we wouldn't know what to do with it. However,
sometime in the future it may eventuate that ADSL or cable modem coverage
will improve.
Apart from the (promise or otherwise) higher bandwidth, the other pressure
that is present is the integration and support of new features or protocols.
The Internet has been a fertile proving ground for the development of new
technology, and even though recent attempts have been made to increase
the core robustness, there is still a rapid uptake of new features.
This creates an ever-growing set of `core' requirements that Internet
devices must encompass to operate in the Internet sphere. Products that
do not keep up are obsoleted. Some of these features are:
-
NAT (Network Address Translation). NAT (along with CIDR) has been one of
the main reasons why the exhaustion of network addresses has been arrested.
It also allows a clean separation between private network addressed domains
and the public Internet. However, NAT can be expensive to do, since it
requires every packet to be examined and the addresses to be modified -
in some cases, even the TCP/UDP port numbers are translated.
-
Security issues. With the recent Denial Of Service attacks on major Internet
servers, it is clear that the Internet is not immune to vandalism, and
in spite of the fact that such attacks may have a social issue at their
source (and consequently may be best addressed in a legal or social forum),
the technology of the Internet must show itself to be robust
against such attacks. This may manifest itself as better firewall mechanisms
(security access lists etc.), more responsive and intelligent intrustion
detection methods, or ways of protecting servers themselves against resource
exhaustion.
-
Quality of Service (QoS). QoS has been a hot topic for Internet research.
The old philosophy of `best effort delivery' may not be suitable in a world
where some customers prefer to pay for `get it there or else', and Differentiated
Services allow for different delivery, billing and priority models. Protocols
such as RSVP allow end-to-end reservation of bandwidth.
-
Integrated Voice/Video. A popular model of operation that has emerged
is the integrated network, where a single IP based network carries pure
data protocols (web, application data, remote sesssions etc.) as well as
voice (VoIP) and video. Whilst much of VoIP applications rely on QoS for
the effective operation, often the underlying transport devices must perform
other services for these applications, such as finer grained fragmentation
etc.
-
Application protocol acceleration. As new applications emerge, it is clear
that new transport layer protocols often accompany these applications,
and with these new protocols come new requirements for network devices.
For example, even with HTTP, new classes of devices are appearing that
perform load balancing or switching based on the URL data within the application
protocol itself, and caching devices exist that accelerate the overall
network by caching the data at a more convenient location.
-
New Protocols. New protocols emerge often as a result of new techniques
or a better understanding of networks. E.g Multi-protocol Label Switching
(MPLS) grew out of a desire to run IP more efficiently over networks like
ATM, but have since been seen as an technology that can be applied to Virtual
Private Networks (VPNs).
-
Future Protocols. IPv6 is still planned as the `next generation' core protocol
for the Internet, though it remains to be seen just when the large scale
deployment of IPv6 will occur. In any case, it is likely that network devices
will
need
to run IPv6 at some point in the future.
The existence of these pressures on the development of network devices
has produced an interesting challenge. Everybody wants the devices to run
10 (or even 100 times faster), but to do 10 (or 100) times as much work!
To put it in crude plumbing terms, it is as if we demanded from our water
supplier as much water to fill our swimming pool in a couple of hours,
but we also want separate pipes for hot water, cold water, spring water,
and water with fertiliser in it for the lawn.
Router Evolution
To understand the environment and need for Network processors, it is useful
to review the evolution of routers and network devices.
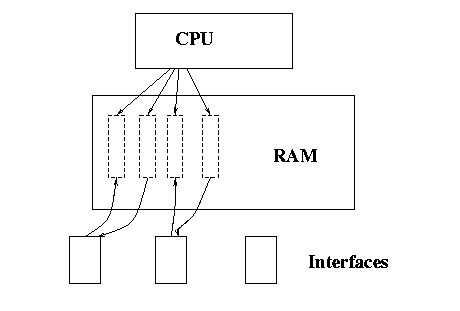
Early routers were simply general purpose embedded systems with network
interfaces attached. The network interfaces would DMA network packets into
a common memory, and the CPU would examine and process the packets, and
then transmit the packet to the output interface.
Whilst this style of router was very general purpose and flexible,
the speed of network interfaces supported was limited to
lower speed serial lines and LAN interfaces (1Mbps up to 45MBps). As
CPU speeds increased, the amount of packet processing could increase, but
the memory subsystem rapidly became a bottleneck.
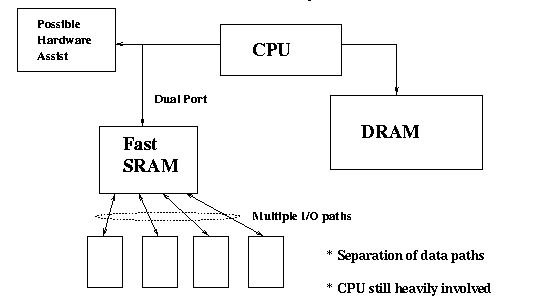
Later generations of routers created a better I/O architecture for
packet processing, where some faster dedicated memory was used to hold
packets in transit, and the CPU had a separate memory bank for code
and data tables. Sometimes specialised ASICs were used to provide hardware
assist (e.g filtering, compression, encryption etc.). The CPU was still
involved in the forwarding of every packet, but the main memory bank was
no longer the bottleneck. Much of the performance is dependant upon careful
tuning of CPU access to the shared packet memory. One part of this was
the need of the CPU to limit its view of the network packets to just the
header, sometimes using a cached write-through view of the packet memory
so that access to multiple header fields could be done efficiently.
This architecture is typical of many routers available on the market
today.
As the core Internet developed in performance requirements, and fibre
optic interface speeds advanced, newer architectures evolved that employed
central crossbar switch matrices fed by high speed line cards (as shown
below).
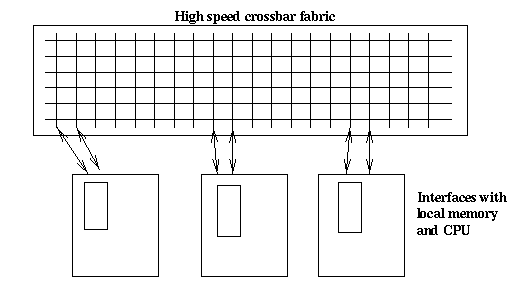
This architecture allowed parallel processing of network packets, as
well as providing redundancy of processing. Each line card may be a simple
hardware line interface, or there may be a local CPU providing some intelligence,
or a custom ASIC may be used to provide faster feature processing. The
higher cost of these architectures meant that only core routers were implemented
this way. The use of CPUs in these line cards meant that more features
could be supported, but at a high performance cost because of the need
to integrate the CPU into the packet path.
However, as higher bandwidth options lowered in cost and became commonly
available, faster processor was required more at the edge of the networks,
but this was also where other more sophisticated features were applied
(NAT, Security, QoS etc.).
Why Network Processors?
An interesting divergence has occurred in the last few years in the world
of CPUs. Traditionally, CPU designers manufacturers have targeted CPUs
at different markets, reflecting the cost or performance required. Typical
Microprocessors were aimed at servers, workstations or PCs. The workloads
expected of these CPUs were generally considered similar, though some systems
were optimised for graphics performance (often through the use of dedicated
co-processors). Much computer science study has centred around the architectural
and performance tradeoffs of these CPUs, leading to the development of
RISC CPUs and other high speed CPUs. A typical CPU these days is orientated
around a high speed central core with a multi-level cache arrangement to
reduce the performance hit of accessing slower main memory. The I/O requirements
of processors is limited to devices that DMA into memory ready for processing
by the CPU. Scaling of processing tasks by general purpose CPUs has been
driven in two directions; increasing clock speed, and the use of multiple
CPUs. Vendors such as Sun Microsystems have very successfully scaled the
performance of the Sparc architecture by concentrating heavily on symmetric
multiprocessing.
Variants of these CPU were often produced by the designers aimed at
particular markets, such as the embedded market. Usually, a different product
cost/performance tradeoff was required, and typically with these embedded
CPUs, a number of support devices are integrated with the CPU to reduce
the overall number of external peripheral devices. These embedded CPUs
were often used as devices in routers and switches, as well as a myriad
of other devices.
An alternative approach to embedded CPUs and general purpose CPUs was
the development of dedicated ASICs, designed specifically for packet network
processing. Typically, these ASICs were proprietary chips, tightly coupled
to a specific product's architecture and design. One advantage of these
ASICs is that the packet performance is considerably greater than a general
purpose CPU, because the ASIC has fixed high speed logic replacing the
general purpose instruction stream. This is, of course, the main disadvantage
of dedicated ASICs, that the time to design and craft the final product
can be as long as 12 months, and the result is inflexible; if new switching
algorithms or protocols need to be supported, a whole new ASIC needs to
be designed.
The common feature of the embedded CPUs was that the CPU was still a
general purpose CPU, albeit with extra support or integration making it
attractive in that environment, and the design was orientated around the
original general purpose workload.
This workload is actually very disjoint from the optimal workload for
devices performing high speed processing of network packets, and as routers
evolved through the designs shown, it was becoming increasingly clear that
general purpose CPUs were not suitable for more advanced processing of
network packets, for the following reasons:
-
The memory architecture of general purpose CPUs essentially involve a heirarchy
of memory starting at primary cache, secondary cache, DRAM, mass storage
etc. The design of the memory architecture centres around the CPU having
fast access to a large memory space, with cache designs maximising bus
utilitisation.
-
So that packets can be processed easily by CPUs, the packets are usually
DMA'ed into some fast memory that allows dual-ported access by network
devices and the CPU. However, whilst this architecture suits the CPU, it
does require that the network packet traverses the memory bus twice. Only
by using very high speed SRAM can the faster interfaces be supported, and
even then the size and cost limitations of SRAM means that only a limited
amount of memory can be supported.
-
The cache architecture of general purpose CPUs do not fit the short-term
processing of packet headers.
-
The memory bandwidth of general purpose CPUs is not great enough to provide
high speed processing of network packets without suffering memory latencies
and delays that effectively serialise and slow the processing of packets.
-
It would be useful to have dedicated instructions for certain processing
of network packets (fletcher checksum etc.).
-
Integration of hardware assist is lacking (CAMs etc.).
-
The I/O architecture of general purpose CPUs does not fit the flow of network
packets.
-
A higher work-per-cycle ratio is often needed for network processing, so
that high speed interfaces (OC-3, OC-12, OC-48, GE) can be supported.
-
Network processing does not lend itself to symmetric multiprocessors, mainly
because the memory bandwidth for common data structures is still a bottleneck.
These requirements have spawned a separate class of processor termed Network
or Communication Processors, which are CPUs designed and architected specifically
to meet the needs of high speed data communications packet processing.
Cisco has developed its own breed of Network Processor, which is officially
termed PXF (Packet eXpress Forwarder), but is known unofficially as Toaster.
Toaster
Toaster is a programmable packet switching ASIC consisting of an embedded
array of cpu cores and several external memory interfaces. The chip may
be programmed to partition packet processing as one very long pipeline,
or into several short pipelines operating in parallel. It is designed primarily
to process IP packets at very high rates using existing forwarding algorithms,
though it may also be programmed to perform other tasks and protocols.
Toaster is composed of an array of 16 CPUs, arranged as 4 rows and columns.
The core CPUs are a cisco designed CPU optimised for packet processing.
A key aspect of toaster is that it is highly programmable, i.e it
is not a dedicated ASIC with fixed set of functions or features that cannot
be extended.
In a purely parallel multiprocessor chip, each cpu core needs shared
or private access to instruction memory for the complete forwarding code.
This was ruled out both because it was an inefficient use of precious internal
memory, and because it would be difficult to efficiently schedule external
data accesses with so many processors running at different places in the
code path. An alternative is to lay out the datapath into a very long pipeline;
this conserves internal code space, since each processor executes only
a small stage of the packet switching algorithm. One drawback of this approach
is that it is difficult to break the code up into 16 different stages of
equivalent duration. Another problem with the very long pipeline is the
overhead incurred in transferring context from one processor to the next
in a high bandwidth application.
Toaster's multiprocessor strategy is to aim at a configurable sweet
spot between fully parallel and fully pipelined. The normal Toaster mode
has all processors in a row operating as a pipeline, while all processors
in a column operate in parallel with a shifted phase. Packets that enter
Toaster are multiplexed into the first available processor row. In this
mode, packets work their way across the pipeline synchronously at one fourth
the rate that packets enter the chip. When a packet reaches the end of
a row, it may exit the chip and/or pass back around to the first processor
of the next logical row. This facilitates packet replication for applications
such as multicast and fragmentation, as well as enabling the logical pipeline
to extend for more than four cpu stages.
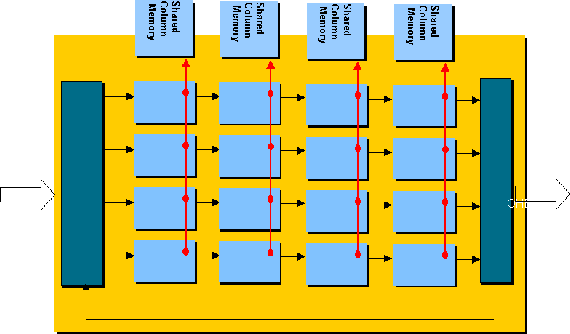
Each column of CPUs share the same instructions, downloaded by a supporting
embedded general purpose CPU (which also manages the housekeeping functions,
boots the system etc). Each column supports a 32 bit memory interface which
can be either SDRAM (up to 256Mb) or SRAM. A small amount of on-chip shared
internal column memory exists, and each CPU has a 128 byte local memory
block.
The current generation of toaster is implemented in .20um technology
with a 1.8V core, operating at a system clock speed of 100MHz.
Dataflow Concept
Toaster is fundamentally different from general purpose CPUs, because it
is based on a packet dataflow model where the packet data passes
through
the ASIC rather than the typical centralised CPU model where the CPU fetches
the data from external memory. Apart from the 4 column memory interfaces,
two separate 64 bit wide high speed interfaces provide the input and output
paths of the packet data; these two interfaces are complementary so that
the output of one toaster ASIC can be joined to the input of another to
provide a deeper pipeline for more sophisticated packet processing. The
interfaces can operate at full system clock speed for a maximum throughput
of 6.4Gbps.
As an analogy, one of the most significant manufacturing breakthroughs
of the 20th century came with the invention of the asembly line in the
Ford Motor Company. The concept was simple. Previously, a car was built
by laying the chassis out on a factory floor, and then workers would bring
parts and assemble the vehicle in the same spot. This complicated the manufacturing
process, because limited workers could operate on the vehicle, and parts
stocking and supply was an issue. The assembly line revolutionised this
process by placing the car on a moving assembly line that allowed specialised
workers access to the vehicle at the appropriate time, simplifying the
parts supply and access. When more automation was applied to manufacturing,
this allowed a faster and more efficient processing of the assembly line.
In terms of packet processing, toaster is the equivalent of an assembly
line, where the packets move through toaster, having dedicated CPU resources
applied to the packets according to the desired functionality. Rather than
operating with primary caches dedicated to holding much used data, toasters'
CPUs have high speed access to the packet data itself, inverting the memory
latencies normally suffered when using general purpose CPUs with network
packet processing. Each packet header is passed through toaster as a 128
byte context. Copying of this context down the row automatically occurs
as a hardware background operation while the CPU is operating on the packet
data, removing any overhead of transferring the packet data to the next
CPU in the pipeline.
Core CPU Details
The toaster CPU design is highly optimised for packet processing, with
the following features:
-
Dual instruction decode and ALUs to allow two instruction issues per clock
cycle
-
64 bit long instruction words allowing two general purpose instructions
(one to each ALU) as well as separate micro-ops for branch control, memory
prefetch operations and other control instructions.
-
Specialised instructions for packet processing, such as hash instructions,
checksum processing, atomic indirect memory operations for queueing and
statistics etc.
-
14 32-bit general purpose registers and 2 special registers.
-
16 bit instruction address space, 32 bit data address space.
-
Support for 8, 16, 32 and 64-bit data types.
-
Multi-way conditional branching.
-
Compound-function ALU that provides combined shift and mask with arithmetic
operations.
-
High performance memory interface, dedicated instruction bus plus two data
interfaces to support simultaneous memory fetch and store operations.
One interesting aspect of the toaster core CPU design is the memory subsystem.
Prefetch micro-ops can be used to prefetch memory values so that maximum
use can be made of the dead cycles normally caused by memory latency delays.
These memory operations can be scheduled so that maximum memory bandwidth
is obtained (often important, since 4 CPUs in a column share the same column
memory interface).
Software Considerations
Because of the uncompromising performance requirements, developing software
for toaster is essentially a microcoding problem, because each CPU
instruction allows up to 2 general purpose instructions and 3 micro-ops.
To get the most out of toaster, it is key to write and develop efficient
microcode. One of the side-effects of the performance requirements is that
much of the machine architecture is exposed to the programmer - for better
or worse. Some of the more exciting challenges that toaster presents for
the average software engineer are:
-
Using the dual issue instructions to maximise the work done for each cycle.
-
Use memory prefetching so that work can be achieved in the cycles while
values are being fetched from memory.
-
One cycle write delays to the register file mean that when a value is transferred
to a register, the value is not seen until one cycle after that instruction.
To alleviate this, special bypass registers can be accessed to retrieve
the previous results of either of the ALUs. The cycle delay means that
bizarre code can be written to access the old value of the register
that is still present in the instruction after the instruction where the
new value is written!
-
Similar to most RISC CPUs, toaster has a branch delay slot where the instruction
after a branch is fetched and executed. Unlike RISC CPUs, however, a micro-op
qualifier can optionally cancel the delay slot instruction if a branch
is taken.
Results
With the use of the background context data mover, a minimum of 64 CPU
cycles can be applied to every packet header for each CPU in toaster. This
provides a maximum processing rate of 6 Million packets per second. At
this rate, some 512 CPU instructions can be applied to every network
packet. A great deal can be done in those cycles, such as NAT processing,
access list security filtering, IP routing, quality of service shaping
and policing etc. This is approximately twice as fast as any other Network
Processor currently available in the market.
The programmability of toaster has shown itself to be a significant
advantage over dedicated ASICs, yet not at the expense of performance,
so that new algorithms and improvements can be delivered without any hardware
changes. This is critical, especially as Internet years seem to grow shorter
all the time.
The first product from Cisco incorporating toaster was announced and
shipped in March of this year (C7200-NSE)
and it is expected that toaster will become a significant building block
in the delivery of products that allow the Internet to continue to grow
and develop at the rate seen so far.